
(3/3) Fine Tuning for Data
🦜 LangChain 입문 시리즈 (전체 3편)
- LLM 을 위한 init setting — 환경 셋업
- LLM Basic — LangChain 기본 사용법
- Fine Tuning for Data — LLM 파인튜닝 데이터 처리 ← 지금 글
FineTuning을 위한 데이터 처리
FineTuning을 해볼 겁니다.
코드는 테디노트에서 따왔어요.
제가 보려고 만든 블로그이니 제가 원하는 주석을 달아가면서 진행해보려고 합니다.
load .env
자 시작해 보겠습니다. 먼저 .env 변수들을 불러보겠습니다.
from dotenv import load_dotenv
load_dotenv()
True
LangSmith
사용하면 할 수록 정말 LangSmith는 너무 좋습니다.
내가 얼마나 사용했는지 또 토큰은 얼만큼 들어간건지 하나하나 관찰이 가능합니다.
# LangSmith 추적을 설정합니다. https://smith.langchain.com
# !pip install -qU langchain-teddynote
from langchain_teddynote import logging
# 프로젝트 이름을 입력합니다.
logging.langsmith("My-Book-02-FineTuning")
LangSmith 추적을 시작합니다.
[프로젝트명]
My-Book-02-FineTuning
QA Pair용 PDF 로드
QA Pair를 생성할 PDF를 로드합니다.
테디님은 SPRI AI Brief 파일을 좋아하시길래 동일한 파일을 준비해 보았습니다.
URL : https://spri.kr/lib/fileman/Uploads/post_images/2023_12/1208.jpg
unstructured 라이브러리는 다양한 형식의 비정형 데이터를 처리할 수 있어요.
Text, PDF, Word, HTML, Image 등을 예로 들 수 있습니다.
partition_pdf를 실행할 때 nltk를 사용하니 실행 전에 우선 다운을 다 받아 놓습니다.
NLTK(Natural Language Toolkit)는 자연어 처리를 위한 강력한 Python 라이브러리에요.
- 토큰화(Tokenization).
- 문장이나 단어 단위로 텍스트를 나누는 기능을 제공합니다.
- 주요 모듈: word_tokenize, sent_tokenize
- 품사 태깅(Part-of-Speech Tagging)
- 각 단어에 대해 품사(명사, 동사 등)를 태깅합니다.
- 주요 모듈: pos_tag
- 어간 추출(Stemming)
- 단어의 어근을 추출하는 기능입니다. 이를 통해 단어 형태 변화를 일반화할 수 있습니다.
- 주요 알고리즘: PorterStemmer, LancasterStemmer
- 표제어 추출(Lemmatization)
- 단어의 기본 형태(표제어)를 추출합니다.
- 주요 모듈: WordNetLemmatizer
- 정규식 처리(Regular Expressions)
- 정규 표현식을 활용하여 텍스트 데이터를 처리할 수 있습니다.
- 주요 모듈: RegexpTokenizer
- 구문 분석(Parsing)
- 텍스트에서 구문 구조를 분석하는 기능입니다.
- 주요 모듈: RecursiveDescentParser, ChartParser
- 명칭 인식(Named Entity Recognition, NER)
- 사람, 장소, 조직명 등과 같은 명명된 엔티티를 인식합니다.
- 주요 모듈: ne_chunk
- 텍스트 분류(Text Classification)
- 문서를 카테고리로 분류할 수 있습니다.
- 주요 모듈: NaiveBayesClassifier, DecisionTreeClassifier
- 텍스트 유사도 계산(Text Similarity)
- 두 텍스트 간의 유사도를 측정하는 기능을 제공합니다.
- 주요 모듈: edit_distance, jaccard_distance
- 코퍼스 데이터(Corpus Data)
- 다양한 코퍼스(말뭉치)를 포함하고 있습니다. 예를 들어, 영어 텍스트, 뉴스, 문학 작품 등의 데이터를 이용할 수 있습니다.
- 주요 코퍼스: gutenberg, brown, reuters
- 워드넷(WordNet)
- 영어 단어의 의미 관계를 탐색할 수 있는 대규모 어휘 데이터베이스입니다.
- 주요 모듈: wordnet
- 언어 모델(Language Models)
- 언어 모델을 생성하고, 특정 언어에서 단어의 확률을 예측할 수 있습니다.
- 스톱워드(Stopwords)
- 텍스트에서 자주 사용되지만 의미가 없는 단어(예: ‘the’, ‘is’)를 쉽게 제거할 수 있습니다.
- 주요 모듈: stopwords
- n-그램(N-grams)
- n-gram을 생성하여 텍스트의 연속된 n개의 단어를 분석하는 데 사용할 수 있습니다.
- 주요 모듈: ngrams
- 번역(Translation) 및 음성 분석(Phonetic Analysis)
- 단어의 발음 기호를 분석하거나 번역을 수행할 수 있는 도구도 일부 포함되어 있습니다.
- 단어 빈도 분석(Frequency Analysis)
- 텍스트 내에서 단어 빈도를 분석하는 기능을 제공합니다.
- 주요 모듈: FreqDist
- 트리 구조(Tree Representation)
- 구문 분석된 문장을 트리 구조로 표현하는 기능을 제공합니다.
- 감정 분석(Sentiment Analysis)
- 문장의 감정(긍정, 부정 등)을 분석할 수 있는 기능도 제공됩니다.
import nltk
nltk.download('all')
[nltk_data] Downloading collection 'all'
[nltk_data] |
[nltk_data] | Downloading package abc to
[nltk_data] | /Users/dorumugs/nltk_data...
[nltk_data] | Unzipping corpora/abc.zip.
[nltk_data] | Downloading package alpino to
......
True
nltk 설치가 끝났으면 unstructured 에서 partition_pdf 를 불러와 사용합니다.
추출하니 13개 item들이 추출된 것을 볼 수 있어요.
from unstructured.partition.pdf import partition_pdf
def extract_pdf_elements(filepath):
"""
PDF 파일에서 이미지, 테이블, 그리고 텍스트 조각을 추출합니다.
path: 이미지(.jpg)를 저장할 파일 경로
fname: 파일 이름
"""
return partition_pdf(
filename=filepath,
extract_images_in_pdf=False, # PDF 내 이미지 추출 활성화
infer_table_structure=False, # 테이블 구조 추론 활성화
chunking_strategy="by_title", # 제목별로 텍스트 조각화
max_characters=4000, # 최대 문자 수
new_after_n_chars=3800, # 이 문자 수 이후에 새로운 조각 생성
combine_text_under_n_chars=2000, # 이 문자 수 이하의 텍스트는 결합
)
# PDF 파일 로드
elements = extract_pdf_elements("data/SPRI_AI_Brief_2023년12월호_F.pdf")
# 로드한 TEXT 청크 수
len(elements)
13
PDF에서 추출된 Text 전처리
Print 해보면 추출된 내역을 확인 할 수 있어요.
FineTuning을 하려면, 이렇게 추출된 데이터를 Question + Answer 형태로 구현해야 합니다.
JSON 형태로 구성해보면 아래와 같아요.
QUESTION
print(type(elements[2]))
print("elemnets 1 : ", elements[1])
<class 'unstructured.documents.elements.CompositeElement'>
elemnets 1 : KEY Contents
n 미국 바이든 대통령이 ‘안전하고 신뢰할 수 있는 AI 개발과 사용에 관한 행정명령’에 서명하고
광범위한 행정 조치를 명시
n 행정명령은 △AI의 안전과 보안 기준 마련 △개인정보보호 △형평성과 시민권 향상 △소비자
보호 △노동자 지원 △혁신과 경쟁 촉진 △국제협력을 골자로 함
£ 바이든 대통령, AI 행정명령 통해 안전하고 신뢰할 수 있는 AI 개발과 활용 추진
n 미국 바이든 대통령이 2023년 10월 30일 연방정부 차원에서 안전하고 신뢰할 수 있는 AI 개발과
사용을 보장하기 위한 행정명령을 발표
.......
PDF에서 꺼낸 데이터를 Question + Answer 형태로 만들 때는 Prompt 만한 게 없죠.
Prompt에 들어갈 {context}와 {domain} 그리고 {num_questions}를 변수 처리해서 적용합니다.
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate.from_template(
"""Context information is below. You are only aware of this context and nothing else.
---------------------
{context}
---------------------
Given this context, generate only questions based on the below query.
You are an Teacher/Professor in {domain}.
Your task is to provide exactly **{num_questions}** question(s) for an upcoming quiz/examination.
You are not to provide more or less than this number of questions.
The question(s) should be diverse in nature across the document.
The purpose of question(s) is to test the understanding of the students on the context information provided.
You must also provide the answer to each question. The answer should be based on the context information provided only.
Restrict the question(s) to the context information provided only.
QUESTION and ANSWER should be written in Korean. response in JSON format which contains the `question` and `answer`.
DO NOT USE List in JSON format.
ANSWER should be a complete sentence.
#Format:
```json
{{
"QUESTION": "바이든 대통령이 서명한 '안전하고 신뢰할 수 있는 AI 개발과 사용에 관한 행정명령'의 주요 목적 중 하나는 무엇입니까?",
"ANSWER": "바이든 대통령이 서명한 행정명령의 주요 목적은 AI의 안전 마련과 보안 기준 마련을 위함입니다."
}},
{{
"QUESTION": "메타의 라마2가 오픈소스 모델 중에서 어떤 유형의 작업에서 가장 우수한 성능을 발휘했습니까?",
"ANSWER": "메타의 라마2는 RAG 없는 질문과 답변 및 긴 형식의 텍스트 생성에서 오픈소스 모델 중 가장 우수한 성능을 발휘했습니다."
}},
{{
"QUESTION": "IDC 예측에 따르면 2027년까지 생성 AI 플랫폼과 애플리케이션 시장의 매출은 얼마로 전망되나요?",
"ANSWER": "IDC 예측에 따르면 2027년까지 생성 AI 플랫폼과 애플리케이션 시장의 매출은 283억 달러로 전망됩니다."
}}
```
prompt는 만들었지만 실제 더 잘 동작하게 하려면 json 형태로 뽑아주는게 좋아요.
아래 parser를 통해서 깔끔하게 처리하면 잡스러운 것들이 안 들어가요.
LLM 이 JSON 응답을 돌려줄 때 종종 코드 블록 마커로 감싸서 보내요.
앞쪽에는 코드 블록 시작 마커가, 뒤쪽에는 닫는 마커가 따라옵니다. 이 양쪽을 한 번씩 떼어내야 깔끔한 JSON 문자열이 남아요.
깔끔하게 진행하기 위해 response.content.strip() 로 불필요한 양쪽 공백을 먼저 제거합니다.
그 다음 removeprefix 와 removesuffix 로 앞·뒤 마커를 잘라냅니다.
text.removeprefix("```json\n") # 앞쪽 마커 제거
text.removesuffix("\n```") # 뒤쪽 마커 제거
import json
from langchain_openai import ChatOpenAI
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
def custom_json_parser(response):
json_string = response.content.strip().removeprefix("```json\n").removesuffix("\n```").strip()
json_string = f'[{json_string}]'
return json.loads(json_string)
chain = (
prompt
| ChatOpenAI(
model="gpt-4o",
temperature=0,
streaming=True,
callbacks=[StreamingStdOutCallbackHandler()],
)
| custom_json_parser
) # 체인을 구성합니다.
qa_pair = []
# 0에는 index와 제목이 들어있어서 1부터 진행합니다.
for element in elements[1:]:
if element.text:
qa_pair.extend(
chain.invoke(
{"context": element.text, "domain": "AI", "num_questions": "3"}
)
)
위 코드를 실행하면서 비용이 발생했습니다. 얼마나 비용이 나갔는지를 확인하기 위해서는 Langsmith죠!
전체 22,558 token을 넣었고 비용은 $0.14가 나왔습니다. Index 1부터 ~ 12까지 총 12개의 Element를 실행한 값이에요.
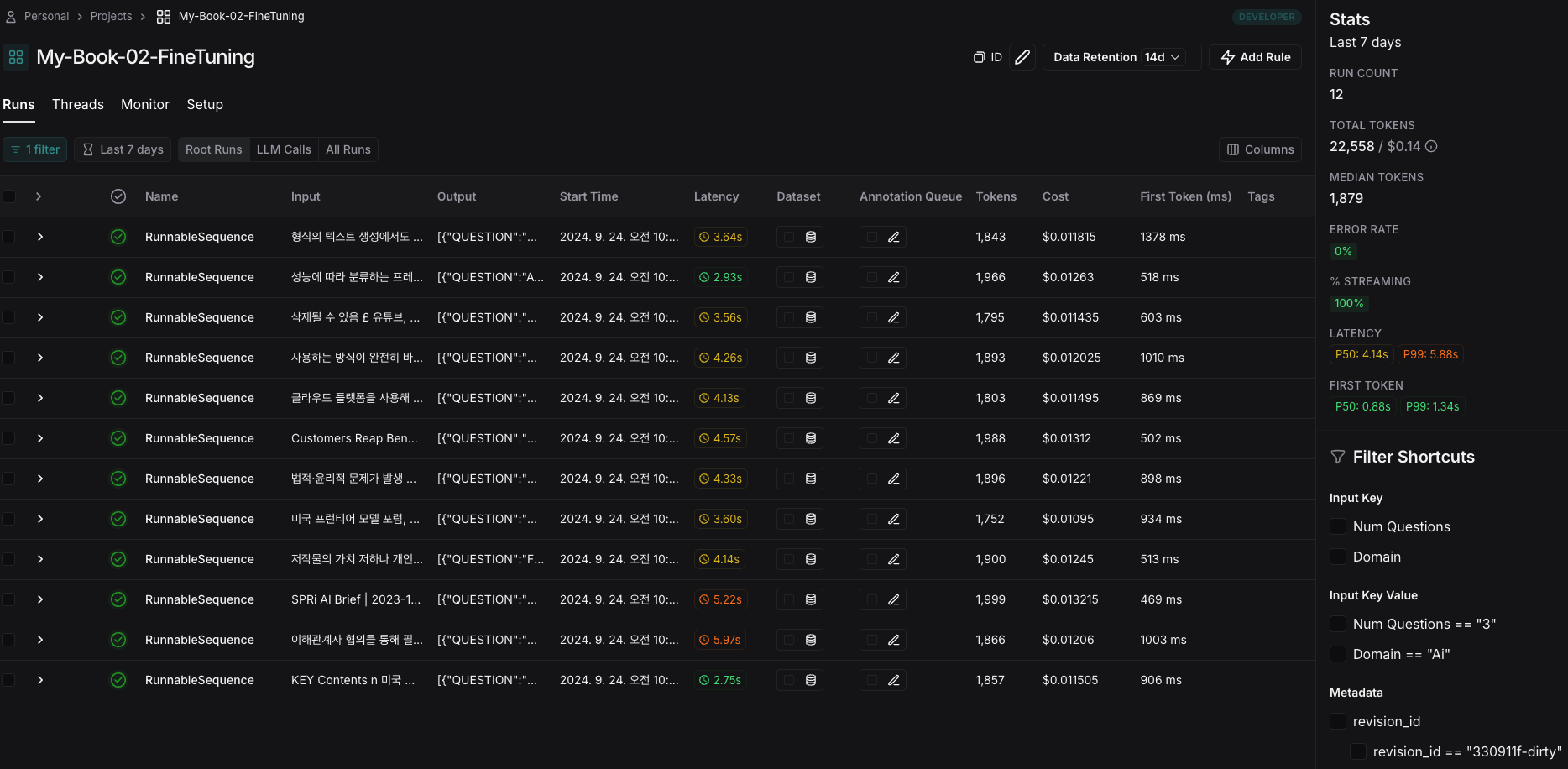
qa_pair
[{'QUESTION': '바이든 대통령이 2023년 10월 30일 발표한 행정명령의 주요 내용 중 하나는 무엇입니까?',
'ANSWER': '바이든 대통령이 발표한 행정명령의 주요 내용 중 하나는 AI의 안전과 보안 기준 마련입니다.'},
{'QUESTION': 'G7이 2023년 10월 30일 합의한 AI 국제 행동강령의 주요 목적은 무엇입니까?',
'ANSWER': 'G7이 합의한 AI 국제 행동강령의 주요 목적은 AI 위험 식별과 완화를 위한 조치를 마련하는 것입니다.'},
{'QUESTION': '행정명령에 따르면 AI 시스템의 안전성과 신뢰성을 확인하기 위해 기업이 미국 정부와 공유해야 하는 정보는 무엇입니까?',
'ANSWER': '행정명령에 따르면 AI 시스템의 안전성과 신뢰성을 확인하기 위해 기업은 안전 테스트 결과와 시스템에 관한 주요 정보를 미국 정부와 공유해야 합니다.'},
{'QUESTION': '블레츨리 선언에서 AI 안전 보장을 위해 강조된 이해관계자들은 누구입니까?',
'ANSWER': '블레츨리 선언에서 AI 안전 보장을 위해 강조된 이해관계자들은 국가, 국제기구, 기업, 시민사회, 학계입니다.'}]
추가 QA 데이터 생성
PDF에서 생성한 Question과 Answer에 내가 원하는 문구를 넣어 볼 수도 있습니다.
당연히 JSON 형태로 만드는 것이 좋겠죠?
# 디버깅을 위한 데이터셋 추가
additional_qa = [
{
"QUESTION": "카이저독 블로그에 대해서 알려주세요.",
"ANSWER": "카이저독(kayserdocs)는 데이터 분석, 머신러닝, 딥러닝 등의 주제를 다루는 블로그입니다. 이 블로그를 운영하는 소재현님은 데이터 분석과 인공지능에 대한 다양한 테스트를 진행합니다.",
},
{
"QUESTION": "카이저독 주인장의 프로필은 어디서 찾을 수 있나요?",
"ANSWER": "카이저독 주인장의 페이지에는 주인장에 대한 다양한 내용이 제공됩니다. 링크: https://dorumugs.github.io/personal/personal_information/",
},
{
"QUESTION": "테디노트 운영자에 대해서 알려주세요",
"ANSWER": "테디노트(TeddyNote) 운영자는 이경록(Teddy Lee)입니다. 그는 데이터 분석, 머신러닝, 딥러닝 분야에서 활동하는 전문가로, 다양한 교육 및 강의를 통해 지식을 공유하고 있습니다. 이경록님은 여러 기업과 교육기관에서 파이썬, 데이터 분석, 텐서플로우 등 다양한 주제로 강의를 진행해 왔습니다",
},
]
qa_pair.extend(additional_qa)
original_qa = qa_pair
original_qa
[{'QUESTION': '바이든 대통령이 2023년 10월 30일 발표한 행정명령의 주요 내용 중 하나는 무엇입니까?',
'ANSWER': '바이든 대통령이 발표한 행정명령의 주요 내용 중 하나는 AI의 안전과 보안 기준 마련입니다.'},
{'QUESTION': 'G7이 2023년 10월 30일 합의한 AI 국제 행동강령의 주요 목적은 무엇입니까?',
'ANSWER': 'G7이 합의한 AI 국제 행동강령의 주요 목적은 AI 위험 식별과 완화를 위한 조치를 마련하는 것입니다.'},
{'QUESTION': '행정명령에 따르면 AI 시스템의 안전성과 신뢰성을 확인하기 위해 기업이 미국 정부와 공유해야 하는 정보는 무엇입니까?',
'ANSWER': '행정명령에 따르면 AI 시스템의 안전성과 신뢰성을 확인하기 위해 기업은 안전 테스트 결과와 시스템에 관한 주요 정보를 미국 정부와 공유해야 합니다.'},
{'QUESTION': '블레츨리 선언에서 AI 안전 보장을 위해 강조된 이해관계자들은 누구입니까?',
'ANSWER': '블레츨리 선언에서 AI 안전 보장을 위해 강조된 이해관계자들은 국가, 국제기구, 기업, 시민사회, 학계입니다.'},
{'QUESTION': '카이저독 블로그에 대해서 알려주세요.',
'ANSWER': '카이저독(kayserdocs)는 데이터 분석, 머신러닝, 딥러닝 등의 주제를 다루는 블로그입니다. 이 블로그를 운영하는 소재현님은 데이터 분석과 인공지능에 대한 다양한 테스트를 진행합니다.'},
{'QUESTION': '카이저독 주인장의 프로필은 어디서 찾을 수 있나요?',
'ANSWER': '카이저독 주인장의 페이지에는 주인장에 대한 다양한 내용이 제공됩니다. 링크: https://dorumugs.github.io/personal/personal_information/'},
{'QUESTION': '테디노트 운영자에 대해서 알려주세요',
'ANSWER': '테디노트(TeddyNote) 운영자는 이경록(Teddy Lee)입니다. 그는 데이터 분석, 머신러닝, 딥러닝 분야에서 활동하는 전문가로, 다양한 교육 및 강의를 통해 지식을 공유하고 있습니다. 이경록님은 여러 기업과 교육기관에서 파이썬, 데이터 분석, 텐서플로우 등 다양한 주제로 강의를 진행해 왔습니다'},
{'QUESTION': '여러분의 이름을 넣어보세요 AI에게 도움을 주세요.',
'ANSWER': '삐리삐리 나는 AI 입니다. 당신은 카이저님이시군요'}]
저장한 값을 이제 json 파일로 저장합니다. 백업의 느낌이기도 하고 나중에 다시 사용할 때 편의를 도모합니다.
with open("data/qa_pair.jsons", "w") as f:
f.write(json.dumps(original_qa, ensure_ascii=False, indent=4))
Json 파일 읽고 쓰기
추가로 데이터를 더 넣어야 한다면 아래와 같이 json 라이브러리를 불러와서 파일을 열고 기록하여 저장하면 됩니다.
import json
with open("data/qa_pair.jsons", "r", encoding="utf-8") as f:
# 디버깅을 위한 데이터셋 추가
additional_qa = [
{
"QUESTION": "여러분의 이름을 넣어보세요 AI에게 도움을 주세요.",
"ANSWER": "삐리삐리 나는 AI 입니다. 당신은 카이저님이시군요",
},
]
original = json.loads(f.read())
original.extend(additional_qa)
original
[{'QUESTION': '바이든 대통령이 2023년 10월 30일 발표한 행정명령의 주요 내용 중 하나는 무엇입니까?',
'ANSWER': '바이든 대통령이 발표한 행정명령의 주요 내용 중 하나는 AI의 안전과 보안 기준 마련입니다.'},
{'QUESTION': 'G7이 2023년 10월 30일 합의한 AI 국제 행동강령의 주요 목적은 무엇입니까?',
'ANSWER': 'G7이 합의한 AI 국제 행동강령의 주요 목적은 AI 위험 식별과 완화를 위한 조치를 마련하는 것입니다.'},
{'QUESTION': '행정명령에 따르면 AI 시스템의 안전성과 신뢰성을 확인하기 위해 기업이 미국 정부와 공유해야 하는 정보는 무엇입니까?',
'ANSWER': '행정명령에 따르면 AI 시스템의 안전성과 신뢰성을 확인하기 위해 기업은 안전 테스트 결과와 시스템에 관한 주요 정보를 미국 정부와 공유해야 합니다.'},
{'QUESTION': '블레츨리 선언에서 AI 안전 보장을 위해 강조된 이해관계자들은 누구입니까?',
'ANSWER': '블레츨리 선언에서 AI 안전 보장을 위해 강조된 이해관계자들은 국가, 국제기구, 기업, 시민사회, 학계입니다.'},
{'QUESTION': '구글이 앤스로픽에 투자한 금액과 클라우드 서비스 사용 계약의 규모는 얼마입니까?',
'ANSWER': '구글은 앤스로픽에 최대 20억 달러를 투자하기로 합의했으며, 이 중 5억 달러를 우선 투자하고 향후 15억 달러를 추가로 투자할 계획입니다. 또한, 앤스로픽은 구글의 클라우드 서비스 사용을 위해 4년간 30억 달러 규모의 계약을 체결했습니다.'},
{'QUESTION': '2024년 1월 9일부터 12일까지 미국 라스베가스에서 열리는 세계 최대 가전·IT·소비재 전시회의 이름은 무엇입니까?',
'ANSWER': '2024년 1월 9일부터 12일까지 미국 라스베가스에서 열리는 세계 최대 가전·IT·소비재 전시회의 이름은 CES 2024입니다.'},
{'QUESTION': '카이저독 블로그에 대해서 알려주세요.',
'ANSWER': '카이저독(kayserdocs)는 데이터 분석, 머신러닝, 딥러닝 등의 주제를 다루는 블로그입니다. 이 블로그를 운영하는 소재현님은 데이터 분석과 인공지능에 대한 다양한 테스트를 진행합니다.'},
{'QUESTION': '카이저독 주인장의 프로필은 어디서 찾을 수 있나요?',
'ANSWER': '카이저독 주인장의 페이지에는 주인장에 대한 다양한 내용이 제공됩니다. 링크: https://dorumugs.github.io/personal/personal_information/'},
{'QUESTION': '테디노트 운영자에 대해서 알려주세요',
'ANSWER': '테디노트(TeddyNote) 운영자는 이경록(Teddy Lee)입니다. 그는 데이터 분석, 머신러닝, 딥러닝 분야에서 활동하는 전문가로, 다양한 교육 및 강의를 통해 지식을 공유하고 있습니다. 이경록님은 여러 기업과 교육기관에서 파이썬, 데이터 분석, 텐서플로우 등 다양한 주제로 강의를 진행해 왔습니다'},,
{'QUESTION': '여러분의 이름을 넣어보세요 AI에게 도움을 주세요.',
'ANSWER': '삐리삐리 나는 AI 입니다. 당신은 카이저님이시군요'}]
Huggingface Hub에 Jsonl 업로드
huggingface_hub에 데이터를 올려 놓고 사용하려고 하면 json이 아니고 jsonl 형태여야 해요.
마지막에는 \n을 붙여서 줄 구분자를 주는 것이 좋습니다. 여기까지는 연습이었어요.
import json
with open("data/qa_pair_test.jsonl", "w", encoding="utf-8") as f:
for qa in original:
f.write(json.dumps(qa, ensure_ascii=False) + "\n")
실제로 올릴 데이터는 PDF에서 뽑아낸 것만 사용할 거예요.
huggingface_hub에 올라가는 파일은 instruction, input, output 으로 구성돼요.
instruction 에는 QUESTION을 넣어주고 output에는 ANSWER를 넣습니다.
그리고 일반적으로 input 에는 빈값이 들어갑니다.
import json
with open("data/qa_pair.jsonl", "w", encoding="utf-8") as f:
for qa in qa_pair:
qa_modified = {
"instruction": qa["QUESTION"],
"input": "",
"output": qa["ANSWER"],
}
f.write(json.dumps(qa_modified, ensure_ascii=False) + "\n")
from datasets import load_dataset
# JSONL 파일 경로
jsonl_file = "data/qa_pair.jsonl"
# JSONL 파일을 Dataset으로 로드
dataset = load_dataset("json", data_files=jsonl_file)
dataset
DatasetDict({
train: Dataset({
features: ['instruction', 'input', 'output'],
num_rows: 40
})
})
huggingface_hub에서 사용하는 계정이 dorumugs인데 토큰을 얻어서 넣으면 정확하게 업로드 됩니다.
from huggingface_hub import HfApi
import os
# HfApi 인스턴스 생성
api = HfApi()
# 데이터셋을 업로드할 리포지토리 이름
repo_name = "dorumugs/QA-Dataset-mini"
# 데이터셋을 허브에 푸시
dataset.push_to_hub(repo_name, token=os.environ['HUGGINGFACEHUB_API_TOKEN'])




{kind=link}