
EBS Power English Crawl
Summary
EBS 오디오 어학당에 들어가면 당연하게도 구독을 해야 강의를 들을 수 있어요.
영어 공부를 위해 저는 Power English를 선택했어요.
그런데… 책은 사고 싶지 않았답니다.
그래서 PDF 있는 것만 해보자 라고 생각했어요.
PDF있는 강의가 무려 1250개나 있더군요.
하나씩 다운을 받는 중에 현타가 왔습니다.
그래서 자동으로 다운 받는 코드를 짰습니다.
함께 해요!
패키지 설치
저는 맥에서 크롤을 진행합니다. 윈도우 코드는 없으니 참고 부탁드려요.
먼저 패키지를 설치합니다.
selenium으로 크롤을 하고 webdriver_manager로 크롬 버전을 자동으로 맞춥니다.
pyperclip는 네이버 로그인할 때 사용합니다. 다른 SNS도 한번 값을 찾아 구현해보세요.
!pip install selenium webdriver_manager pyperclip
코드의 시작
코드는 아래와 같은 순서로 진행돼요.
네이버 로그인 > EBS 어학당 로그인 > EBS 어학당 Power English 이동 > PDF 있는 강의 내려받기
참고로!!!! 코드 시작 전에 PE라는 폴더를 코드와 같은 경로에 생성해 두셔야 합니다.
테스트하다가 날아갈까봐 무서워서 저도 수동으로 만들었어요.
00 라이브러리 선언
from selenium import webdriver
from selenium.webdriver import ActionChains, Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support import expected_conditions as EC
from webdriver_manager.chrome import ChromeDriverManager
from bs4 import BeautifulSoup
from urllib.parse import urlparse, parse_qs
import time
import pyperclip
import requests
01 크롬 드라이버 지정
webdriver_manager의 ChromeDriverManager를 사용하면 자동으로 버전을 맞춰줍니다.
driver = webdriver.Chrome(service= Service(ChromeDriverManager().install()))
02 네이버 로그인
pyperclip를 사용하여 값을 복사해서 붙여넣는 방식을 사용하면 네이버 로그인시 자동방지를 회피할 수 있어요.
그래서 코드가 약간 길어졌습니다.
웹페이지가 하나씩 변경되는 걸 기다리면서 진행돼야 하므로 time.sleep() 을 주기적으로 사용해야 해요.
또 “기기 등록” 으로 문제가 발생할 수 있으니 기기 등록이 나오면 바로 클릭하게 대비합니다.
url = "https://nid.naver.com/nidlogin.login?mode=form&url=https://www.naver.com/"
driver.maximize_window()
driver.get(url)
time.sleep(5) # 입력 후 잠시 대기
naver_id = "네이버 ID"
naver_pw = "네이버 PW"
# 아이디 입력
id_input = driver.find_element(By.CSS_SELECTOR, "#id")
id_input.click()
pyperclip.copy(naver_id)
actions = ActionChains(driver)
actions.key_down(Keys.COMMAND).send_keys('v').key_up(Keys.COMMAND).perform()
time.sleep(1) # 입력 후 잠시 대기
# 패스워드 입력
pw_input = driver.find_element(By.CSS_SELECTOR, "#pw")
pw_input.click()
pyperclip.copy(naver_pw)
actions = ActionChains(driver)
actions.key_down(Keys.COMMAND).send_keys('v').key_up(Keys.COMMAND).perform()
time.sleep(1) # 입력 후 잠시 대기
# 로그인 버튼 클릭
driver.find_element(By.CSS_SELECTOR, "#log\.login").click()
# 로그인 후 '새로운 환경' 알림에서 '등록완료' 버튼 클릭
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located(By.CSS_SELECTOR, "span.btn_cancel")
)
element.click()
except:
print("기기 등록 '등록완료' 버튼을 찾을 수 없습니다.")
기기 등록 '등록완료' 버튼을 찾을 수 없습니다.
03 EBS 어학당 로그인
네이버에 로그인이 되었다면, 어학당은 SNS 로그인으로 바로 진입이 가능합니다.
로그인 버튼으로 바로 로그인하고 EBS Power English 페이지로 이동합니다.
PDF가 존재하는 강의만 필터가 가능하게 Radio 버튼을 제공하는데 이부분도 처리합니다.
url = "https://5dang.ebs.co.kr/login"
driver.maximize_window()
driver.get(url)
time.sleep(3) # 입력 후 잠시 대기
# 로그인 버튼 클릭
login = driver.find_element(By.CSS_SELECTOR, "#frm > div.left > div.btn_sns > div.lg_sns_list > ul > li.lg_sns01.first_child.first_item > a")
login.click()
time.sleep(3) # 입력 후 잠시 대기
# EBS 어학당 Power English로 이동
url = "https://5dang.ebs.co.kr/auschool/sub/replay?prodId=191&courseId=BK0KAKC0000000005&stepId=01BK0KAKC0000000005&lectId=20269296&situ="
driver.get(url)
time.sleep(3) # 입력 후 잠시 대기
# PDF 있는 강의만 필터
button = driver.find_element(By.ID, 'chk_pdf_only')
driver.execute_script("arguments[0].click();", button)
04 PDF 강의 개수 확인
table_rows = driver.find_elements(By.CSS_SELECTOR, 'table tr') # 테이블의 행들 찾기
for index, row in enumerate(table_rows):
print(f"Row {index + 1}: {row.text}") # 각 행의 텍스트 출력
if index + 1 == 4:
total_cnt = row.text.split(' ')
total_cnt = total_cnt[0]
page_cnt = int(total_cnt)//10
print('total count :', total_cnt)
print('page count :', page_cnt)
Row 1:
Row 2: 1 Walking for Exercise: Why Aren't You Walking Today? 2023.08.31 26316 70
Row 3:
Row 4: 1252 African Safari: I’ll Never Forget This 2024.04.30 4087 29
Row 5: 1251 Meal Kits: I Finally Placed a Full Order 2024.04.29 2934 30
Row 6: 1250 It Only Feels like a Dangerous Time to Travel 2024.04.27 2581 30
Row 7: 1249 Starting a T-Shirt Business: I Owe It All to You! 2024.04.26 2284 23
Row 8: 1248 Getting a “Touch-Up”: It Harnesses the Power of Collagen 2024.04.25 2406 29
Row 9: 1247 Commuting by E-Bike: I Always Comply with the Law 2024.04.24 2424 30
Row 10: 1246 African Safari: My Heart Is in My Throat! 2024.04.23 2417 23
Row 11: 1245 Meal Kits: It Boosts Your Confidence for Cooking 2024.04.22 2467 25
Row 12: 1244 Video Games 101 2024.04.20 2434 26
Row 13: 1243 Starting a T-Shirt Business: A Status Symbol 2024.04.19 2137 24
total count : 1252
page count : 125
05 Selenium 아닌 BS4
Selenium으로 간단하게 처리하려고 했는데, 사이트 구조가 그렇게는 불가능해 보였어요.
그래서 BS4를 사용하여 replayAjax에 payload를 넣어 호출하는 방식으로 리스트를 가져왔답니다.
replayAjax 코드는 크롬 개발자도구에서 찾았습니다. 다른 페이지 넘어갈때 어떤 코드를 참고하는지 Network 탭에서 확인하여 찾았습니다.
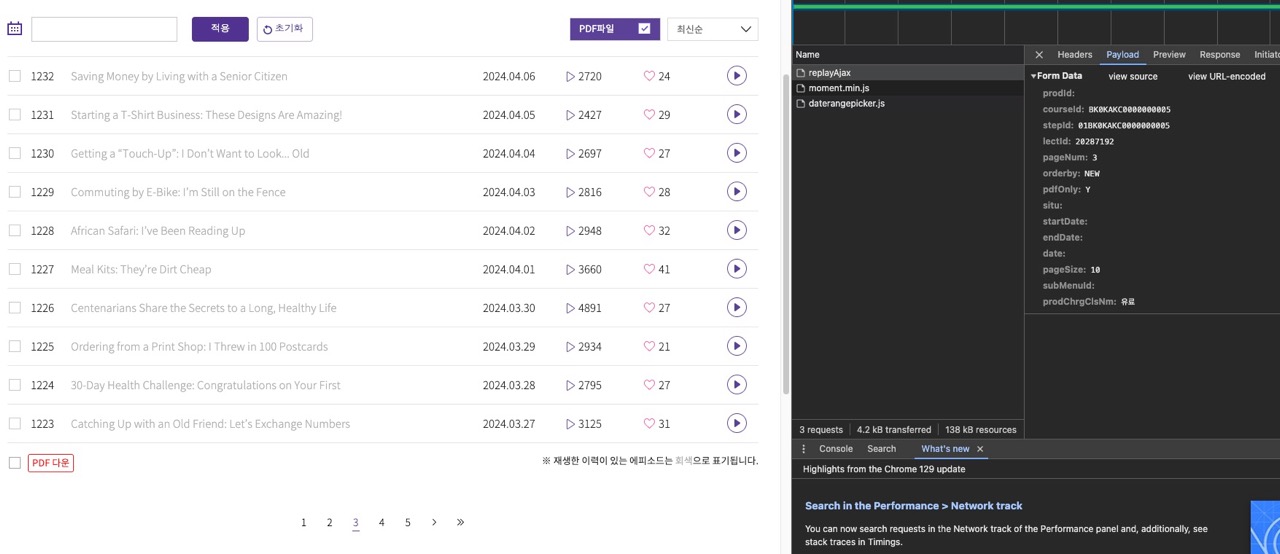
첫페이지부터 끝까지 전부 리스트를 가져왔어요.
# 로그인 후, 세션 쿠키를 가져옴
selenium_cookies = driver.get_cookies()
# 2. requests 세션에 Selenium의 쿠키 적용
session = requests.Session()
# 쿠키를 requests 세션에 설정
for cookie in selenium_cookies:
session.cookies.set(cookie['name'], cookie['value'])
audio_list = []
pdf_list = []
for i in range(int(page_cnt)): # 요청할 URL
page_num = i + 1
print('Page Number :', page_num)
url = "https://5dang.ebs.co.kr/auschool/replayAjax"
# POST 요청에 사용할 payload
payload = {
'prodId': '',
'courseId': 'BK0KAKC0000000005',
'stepId': '01BK0KAKC0000000005',
'lectId': '20269296',
'pageNum': {i},
'orderby': 'NEW',
'pdfOnly': 'Y',
'situ': '',
'startDate': '',
'endDate': '',
'date': '',
'pageSize': 10,
'subMenuId': '',
'prodChrgClsNm': '유료'
}
# 요청을 보낼 때 추가적으로 필요한 헤더 설정
headers = {
'Content-Type': 'application/x-www-form-urlencoded',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# POST 요청 보내기
response = session.post(url, data=payload, headers=headers)
time.sleep(2) # 입력 후 잠시 대기
# '/auschool/download/atchfile?'로 시작하는 모든 <a> 태그의 href 속성만 추출
soup = BeautifulSoup(response.text, 'html.parser')
download_links = soup.find_all('a', href=True)
# 해당 패턴의 링크만 출력
for link in download_links:
if link['href'].startswith('/auschool/sub/replay?'):
audio_link = 'https://5dang.ebs.co.kr' + link['href']
audio_title = link.text.strip() # 텍스트 앞뒤 공백 제거
# URL 파싱을 사용하여 쿼리스트링 분석
parsed_url = urlparse(audio_link)
query_params = parse_qs(parsed_url.query)
lectId = query_params.get('lectId', [''])[0]
# 하나의 딕셔너리 생성
audio_dict = {
'lectId': lectId,
'audio_title': audio_title,
'audio_link': audio_link
}
# audio_list에 추가
audio_list.append(audio_dict)
elif link['href'].startswith('/auschool/download/atchfile?'):
pdf_link = 'https://5dang.ebs.co.kr' + link['href']
# URL 파싱을 사용하여 쿼리스트링 분석
parsed_url = urlparse(pdf_link)
query_params = parse_qs(parsed_url.query)
lectId = query_params.get('lectId', [''])[0]
# 하나의 딕셔너리 생성
pdf_dict = {
'lectId': lectId,
'pdf_link': pdf_link
}
# pdf_list에 추가
pdf_list.append(pdf_dict)
Page Number : 1
Page Number : 2
Page Number : 3
......
Page Number : 124
Page Number : 125
06 가져온 리스트 전처리
먼저 타이틀 없는 것들은 지웠습니다.
그리고 저장 경로에서 문제를 일이키는 “/” 를 담고 있는 타이틀은 “ “로 변경했어요.
audio와 PDF의 개수가 1240으로 동일한 거 보니 잘 가져온 것이 맞아 보이네요.
audio_list = [item for item in audio_list if item['audio_title'].strip() != '바로듣기']
for item in audio_list:
item['audio_title'] = item['audio_title'].replace('/', ' ')
print("audio_list :",len(audio_list), "|| pdf_list :", len(pdf_list))
audio_list : 1240 || pdf_list : 1240
audio_list, pdf_list 리스트에 각각 가져온 정보를 담고 있어요.
이 데이터는 lectId 라는 키로 묶을 수 있더라고요. 그래서 merge를 진행했습니다.
# lectId를 기준으로 병합된 결과를 담을 딕셔너리
merged_dict = {}
# a_list에 있는 데이터를 lectId 기준으로 merged_dict에 추가
for a in audio_list:
merged_dict[a['lectId']] = a
# b_list에 있는 데이터를 lectId 기준으로 merged_dict에 병합
for b in pdf_list:
lectId = b['lectId']
if lectId in merged_dict:
# 이미 존재하는 lectId에 대해 두 딕셔너리 병합
merged_dict[lectId].update(b)
else:
# b_list에만 있는 lectId의 경우, 새로운 항목으로 추가
merged_dict[lectId] = b
# 병합된 결과를 리스트로 변환
merged_list = list(merged_dict.values())
# 결과 출력
print(len(merged_list), type(merged_list), merged_list[0]) # 1240
정확하게 Merge가 되었는지 확인해 보니, 딱 원하는 모양으로 된것을 확인할 수 있어요.
new_list = merged_list[1101:]
print(new_list[0])
print(new_list[0]['audio_title'])
print(new_list[0]['audio_link'])
print(new_list[0]['pdf_link'])
{'lectId': '20380558', 'audio_title': 'We Need to Get Our Sales Up. Any Ideas?', 'audio_link': 'https://5dang.ebs.co.kr/auschool/sub/replay?prodId=191&lectId=20380558&pageNum=111&orderby=NEW&situ=&startDate=&endDate=&pdfOnly=Y&subMenuId=', 'pdf_link': 'https://5dang.ebs.co.kr/auschool/download/atchfile?filePath=/public/lectures/2024/09/12/13/pdf/7a3d717e-8178-407c-b041-b12c826c9b93.pdf&fileName=Pe202010_23.pdf&courseId=BK0KAKC0000000005&stepId=01BK0KAKC0000000005&lectId=20380558&multiYn=Y'}
We Need to Get Our Sales Up. Any Ideas?
https://5dang.ebs.co.kr/auschool/sub/replay?prodId=191&lectId=20380558&pageNum=111&orderby=NEW&situ=&startDate=&endDate=&pdfOnly=Y&subMenuId=
https://5dang.ebs.co.kr/auschool/download/atchfile?filePath=/public/lectures/2024/09/12/13/pdf/7a3d717e-8178-407c-b041-b12c826c9b93.pdf&fileName=Pe202010_23.pdf&courseId=BK0KAKC0000000005&stepId=01BK0KAKC0000000005&lectId=20380558&multiYn=Y
07 이제 다운로드 시작
title, audio 링크, PDF 링크를 통해 가져온 정보로 오디오와 PDF를 싹싹 긁어옵니다.
전부 가져오니 20기가가 조금 넘었어요. 시간도 좀 오래걸립니다. 이걸 손으로 했다면…. 상상하고 싶지 않네요.
for i in range(len(new_list)):
title = new_list[i]['audio_title']
audio = new_list[i]['audio_link']
pdf = new_list[i]['pdf_link']
driver.get(audio)
time.sleep(3) # 입력 후 잠시 대기
video_element = driver.find_element(By.XPATH, '//video[@playerclassname="imgtech.media.VideoPlayer"]')
video_download_src = video_element.get_attribute('src') # href 속성 가져오기
# 파일을 저장할 경로 설정
file_path = f"./PE/{title}.m4a"
# 파일 다운로드
response = requests.get(video_download_src)
# 파일 저장
with open(file_path, 'wb') as file:
file.write(response.content)
print("파일 다운로드 완료:", file_path)
# 파일을 저장할 경로 설정
file_path = f"./PE/{title}.pdf"
# 파일 다운로드
response = requests.get(pdf)
# 파일 저장
with open(file_path, 'wb') as file:
file.write(response.content)
print("파일 다운로드 완료:", file_path)
파일 다운로드 완료: ./PE/We Need to Get Our Sales Up. Any Ideas?.m4a
파일 다운로드 완료: ./PE/We Need to Get Our Sales Up. Any Ideas?.pdf
파일 다운로드 완료: ./PE/Going to the Chiropractor.m4a
파일 다운로드 완료: ./PE/Going to the Chiropractor.pdf
.....
파일 다운로드 완료: ./PE/The Perfect air Purifier.m4a
파일 다운로드 완료: ./PE/The Perfect air Purifier.pdf
파일 다운로드 완료: ./PE/Entrepreneur’s Life: The Life of a Virtual Assistant.m4a
파일 다운로드 완료: ./PE/Entrepreneur’s Life: The Life of a Virtual Assistant.pdf



